前言
作为一枚会撸码爱篮球会写作爱动漫的非二次元吃货程序媛,在前段时间的端午,回家吃了顿饭之后,感受到了来自老爸的厨艺鄙夷以及来自老妈的美味诱惑,于是决定开始我的厨艺生涯.
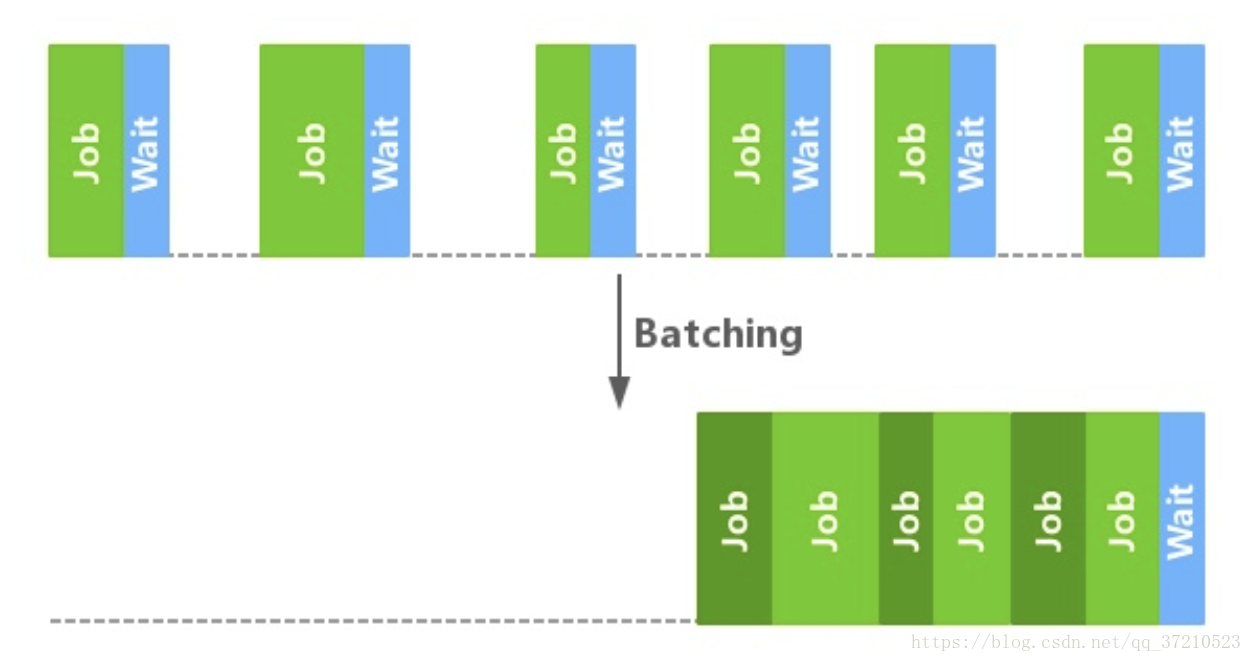
每周解锁一道新品种(哈哈,对于我来说,一切都是新品种)
为啥写博客?
写这个博客呢,只有两个目的:
1.记录一下自己的厨艺成长过程;(真相是,我这人比较懒,立个flag,鞭策一下自己)
2.记录每道菜的制作过程,随手拿来当菜谱用,哈哈!
先秀一波图,走你!
来自老妈的厨艺:


(原谅我手机的渣像素,实物比这好看)
啦啦啦啦,现在就开始我的厨艺表演了!
2018年7月1日 周日
今日午餐菜单: 海带排骨汤、啤酒鸭、素炒鱼丝、甜豆炒瘦肉,外加绿豆汤
新品解锁:啤酒鸭
材料准备:半片鸭、青椒、红椒、葱、姜、蒜、生抽、老抽、盐、八角、啤酒一瓶(只需要用半瓶,但没有半瓶卖,笑哭脸)
制作过程:
步骤一:
先把鸭子剁成块,焯水捞出;
葱姜蒜什么的切好,备用;
(至于切成什么形状,看个人爱好了, 我是把姜切片,辣椒切段了,葱忘记买了,然后辣椒籽弄掉)
步骤二:
炒锅里放油,油热了之后爆炒姜蒜辣椒,葱先不炒,因为熟得快,
然后把配料捞出,再倒点油,把鸭块倒入,中火炸一会,沥出鸭油,因为比较油腻,可以把油倒出一些;
步骤三:
放入盐、生抽、老抽,八角调味,倒入啤酒没过鸭块,半片鸭差不多半瓶的样子,
盖上锅盖,大火煮开,大约十分钟之后转小火慢炖,
把爆炒过的配料倒入,改大火翻炒,之后把葱放入,翻炒收干汁出锅!
大概就是这样了,上菜吧!

等等,打开方式不对,我好像忘记单独拍啤酒鸭了,
不过这么明显的三个菜,啤酒鸭没有不认识的吧?(左边第一盘)
那中间那盘是啥?
这个是特地从家乡带的鱼丝,啥》? 鱼丝你不认识? 出门右转找百度(https://baike.baidu.com/item/鱼丝/7386802?fr=aladdin) 。
说下这个菜的做法吧
大致是这样的:
1.烧开水把鱼丝煮软,沥水捞出备用;
2.姜蒜辣椒爆炒,用姜是因为有鱼腥味(但鱼丝里没有鱼,就跟鱼香肉丝没有鱼是一样的道理,憨笑脸)
3.把鱼丝倒入,加入盐,调味粉等,入味之后出锅装盘,搞定,就是这么简单!
第三盘的甜豆炒肉就没有说的必要啦!
再秀一张完整的图:

总结:炎炎夏日,啤酒配上鸭,绿豆配上汤,排骨配海带,超级享受!
2018年7月8日 周日
今日午餐菜单:海带海粉排骨汤、鸡蛋饼、辣椒炒肉
新品解锁:鸡蛋饼
材料准备:鸡蛋3个,面粉、葱、盐、水、植物油、醋
操作步骤:
1.香葱切细,备用,
用一个稍大一些的碗,倒入一定量的面粉,然后把鸡蛋磕进去,缓缓倒入清水,加入食盐和葱花;
2.用汤匙搅拌均匀,打成可以流淌的面糊状;这一步很关键,不能有面粉结块的现象
3.在锅中倒入植物油,先不加热,用汤匙装一匙面糊淋入锅内,
迅速转动锅子,将粉浆水平摊在锅底成圆饼状,
4.将锅子移到火上,用小火加热至面糊凝固成型,再翻面用小火煎另一面,直到两面都变得有鞋焦黄上色,出锅!
好了,上菜!


额额,只能说还凑合吧,毕竟葱花最后用的青椒代替!(手动表情-捂脸笑)
这个汤,我单独说一下,
里面放了海粉(我也不确定叫法,从家里带的),这个海粉,下火的,夏天炖汤喝贼爽,滑溜溜的。
为了看清原料,我单独来一张图:

诺,就是那个看起来有点点褐黄色的东西,老妈心疼我特别容易上火,走之前给我塞包里,也不知道这边有没有得买。
总结:说啥好呢?这周貌似有点清淡啊!
2018年7月15日 周日
今日早餐菜单:优酸乳 三明治
今日午餐菜单:红烧鱼块 油炸茄子 凉拌萝卜 水果捞
早餐的三明治呢,做法很简单
就是稍微煎一下切片面包,煎一个鸡蛋,煎两片火腿片,生菜忘记放了,夹好,搞定!
直接上图吧!
冰过的牛奶,口感俱佳!

今日新品一:红烧鱼块
材料准备:鱼块、葱、姜、蒜、青椒、红椒、黄酒、盐、五香粉、淀粉,酱油
制作过程:
步骤一:
鱼块洗净切好,放入少许淀粉,五香粉和盐,拌均匀。
步骤二:
将姜蒜辣椒爆炒后装盘,备用;
步骤三:
倒入油,烧热油锅后将鱼块倒入,大火炸几分钟,炸至两边带点焦黄,倒入少许黄酒,酱油、调味粉进行调味,
倒入半碗水,盖上锅盖,大火焖几分钟;
步骤四:
将姜蒜辣椒、葱倒入,进行翻炒入味收汁,出锅!
注意:翻炒时不要将鱼块翻烂,最好是翻一遍就出锅。
上菜吧!

略微有点翻烂了,,卖相不咋地,不过味道还可以啦!
今日新品二:油炸茄子
材料准备:茄子一条,面粉,淀粉、鸡蛋、盐、酱油
制作过程:
步骤一:
将茄子切条,放在冷水中泡大概十分钟左右;
步骤二:
将茄子捞出,加入少许盐和酱油搅拌,腌制片刻让茄子入味;
步骤三:
取一只大碗,将面粉倒入,再加入少许淀粉,打入一个鸡蛋,加一些水搅拌,调成面糊备用;
步骤四:
锅内倒入油,油锅至七八成热时(表面有小气泡翻滚),将腌好的茄子滚在面糊上,下锅内炸,翻面炸至两面焦黄夹出装盘即可!
小提示:
1.腌制师可以加入胡椒粉、辣椒粉等调味料,随你喜欢;
2.炸的时候不宜太大火,中火即可,记得翻面,免得烧焦;
3.调面糊为啥加鸡蛋?因为加鸡蛋可以更脆更香。
嗯,就酱,上菜吧!

然后是午餐完整图来一张:

最后再上几张图,都是日常操作,记不得哪一天的了, 哈哈!